





智能驾驶方向视觉算法研究目前主要两个方向:
视觉SLAM及基于深度学习的视觉检测。
一、基于深度学习(CNN)的视觉检测分两个方向:
1、图像检测
图像检测算法根据速度及准确度排序大致有以下几种:

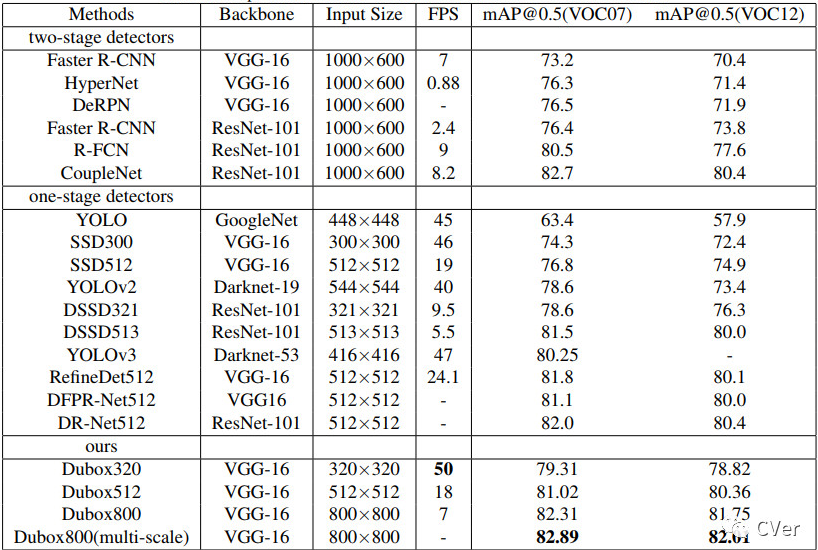
实际应用过程中,在满足速度与准确度的情况下,我们一般选择SSD和YOLO两种算法框架,同时由于受限制于边缘计算的设备的算力,我们一般把网络中的Backbone替换成别的轻量级网络,比如:Squeezenet、Mobilenet、Shufflenet、IGCV、Densenet等,其中Mobilenet最常用。
2、图像分割
图像语义分割优秀算法包括以下几种:
(1)传统语义分割算法是 全卷积CNN+CRF,优秀算法如下:
l U-Net:通过产生原始训练数据的扭曲版而增加训练数据。这一步使 CNN 编码器-解码器变得更加鲁棒以抵抗这些形变,并能从更少的训练图像中进行学习。当它在少于 40 张图的生物医学数据集上训练时,IOU 值仍能达到 92%。
l DeepLab:将 CNN 编码器-解码器和 CRF 精炼过程相结合以产生目标标签(如前文所述,作者强调了解码器的上采样)。空洞卷积(也称扩张卷积)在每一层都使用大小不同的卷积核,使每一层都能捕获各种比例的特征。在 Pascal VOC 2012 测试集中,这个架构的平均 IOU 达到了 70.3%。
l Dilation10:是一种扩张卷积的替代方法。完整流程是将扩张卷积的「前端模块」连接到内容模块上,再用 CRF-RNN 进行下一步处理。通过这样的构造,Dilation10 在 Pascal VOC 2012 测试集上的平均 IOU 值达到了 75.3%。
(2)端到端的语义分割算法:
l FCN-8s、DeepLab 和 CRF-RNN 等,这些方法不是独立地优化不同模块,而是采用端到端的方法。
二、视觉SLAM算法汇总
(1) 传统纯视觉vSLAM主要有以下几步:
只利用相机作为外部感知传感器的SLAM称为视觉SLAM (vSLAM )。相机具有视觉信息丰富、硬件成本低等优点,经典的vSLAM系统一般包含前端视觉里程计、 后端优化、 闭环检测和构图四个主要部分。
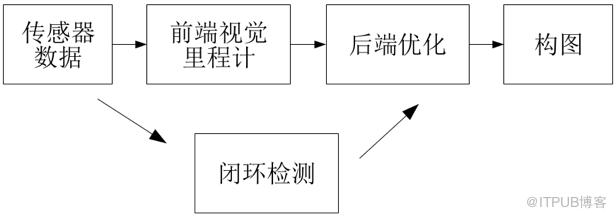
对应的每一步都有相关的算法
传统Visual SLAM 自 PTAM 算法以来,框架基本趋于固定。通常包括 3 个线程,前端 tracking 线程、后端 mapping 优化线程、闭环检测(loop closure)线程。
l 常见的特征点提取算法:
性能上大致可以认为 SIFT > SURF > ORB > FAST,效率上可以认为 FAST > ORB > SURF > SIFT(大于号左边代表更优。性能主要包括匹配精度、特征点的数量和空间分布等)。为了在性能和效率上取得折中,通常采用 FAST 或者 ORB,只能舍弃性能更好的 SIFT、SURF 等。
l VIO(视觉里程计):
代表算法有 EKF、MSCKF、preintegration、OKVIS 等。
l vSLAM:
vSLAM 的代表算法有 ORB-SLAM、SVO、DSO等;
vSLAM 主要有种路线,一种是稀疏点估计法,一种是稠密直接法:
稀疏估计法包括:
MonoSLAM 是第一个实时的单目视觉 SLAM 系统。 MonoSLAM 以EKF(扩展卡尔曼滤波)为后端,追踪前端稀疏的特征点,以相机的当前状态和所有路标点为状态量,更新其均值和协方差。在 EKF 中,每个特征点的位置服从高斯分布,可以用一个椭球表示它的均值和不确定性,它们在某个方向上越长,说明在该方向上越不稳定。

该方法的缺点:场景窄、路标数有限、稀疏特征点易丢失等。
PTAM提出并实现了跟踪和建图的并行化,首次区分出前后端 (跟踪需要实时响应图像数据,地图优化放在后端进行),后续许多视觉SLAM 系统设计也采取了类似的方法。PTAM 是第一个使用非线性优化作为后端的方案,而不是滤波器的后端方案。提出了关键帧 (keyframes)机制,即不用精细处理每一幅图像,而是把几个关键图像串起来优化其轨迹和地图。
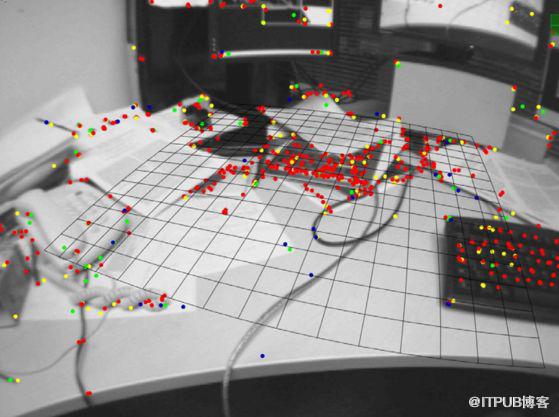
该方法的缺点是:场景小、跟踪容易丢失。
ORB-SLAM围绕ORB 特征计算,包括视觉里程计与回环检测的 ORB字典。ORB 特征计算效率比 SIFT 或 SURF 高,又具有良好的旋转和缩放不变性。ORB-SLAM 创新地使用了三个线程完成 SLAM,三个线程是:实时跟踪特征点的Tracking线程,局部 Bundle Adjustment 的优化线程和全局 Pose Graph 的回环检测与优化线程。该方法的缺点:每幅图像都计算一遍 ORB 特征非常耗时,三线程结构给 CPU带来了较重负担。稀疏特征点地图只能满足定位需求,无法提供导航、避障等功能。
ORB-SLAM2基于单目的 ORB-SLAM 做了如下贡献:第一个用于单目、双目和 RGB-D 的开源 SLAM 系统,包括闭环,重定位和地图重用; RGB-D 结果显示,通过使用 bundle adjustment,比基于迭代最近点(ICP) 或者光度和深度误差最小化的最先进方法获得更高的精度; 通过使用近距离和远距离的立体点和单目观察结果,立体效果比最先进的直接立体 SLAM 更准确; 轻量级的本地化模式,当建图不可用时,可以有效地重新使用地图。
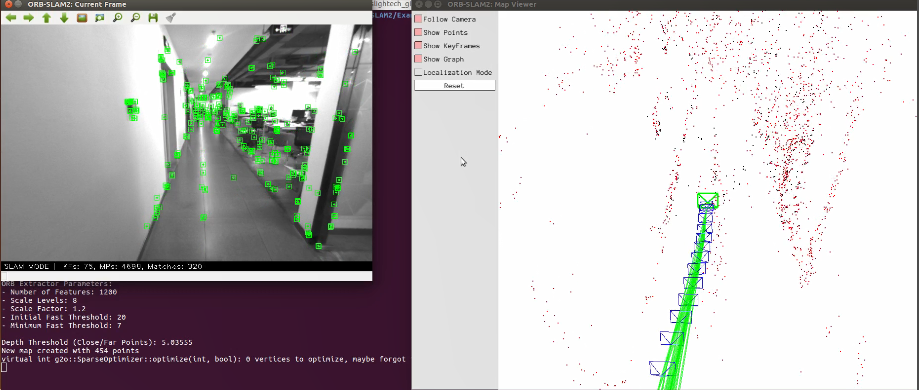
稠密直接法包括:
DTAM是单目 VSLAM 系统, 是一种直接稠密的方法,通过最小化全局空间规范能量函数来计算关键帧构建稠密深度图,而相机的位姿则使用深度地图通过直接图像匹配来计算得到。对特征缺失、 图像模糊有很好的鲁棒性。该方法的缺点是:计算量非常大,需要 GPU 并行计算。 DTAM 假设光度恒定,对全局照明处理不够鲁棒。
LSD-SLAM建了一个大尺度直接单目 SLAM 的框架,提出了一种用来直接估计关键帧之间相似变换、尺度感知的图像匹配算法,在CPU上实现了半稠密场景的重建。该方法的缺点:对相机内参敏感和曝光敏感,相机快速运动时容易丢失,依然需要特征点进行回环检测。

SVO(Semi-direct Visual Odoemtry) 是一种半直接法的视觉里程计,它是特征点和直接法的混合使用:跟踪了一些角点,然后像直接法那样,根据关键点周围信息估计相机运动及位置。由于不需要计算大量描述子,因此速度极快,在消费级笔记本电脑上可以达到每秒 300 帧,在无人机上可以达到每秒 55 帧。该方法的缺点是:舍弃了后端优化和回环检测,位姿估计存在累积误差,丢失后重定位困难。
DSO(Direct Sparse Odometry) 是基于高度精确的稀疏直接结构和运动公式的视觉里程计的方法。不考虑几何先验信息,能够直接优化光度误差。并且考虑了光度标定模型,其优化范围不是所有帧,而是由最近帧及其前几帧形成的滑动窗口,并且保持这个窗口有 7 个关键帧。DSO 中除了完善直接法位姿估计的误差模型外,还加入了仿射亮度变换、 光度标定、 深度优化等。该方法没有回环检测。
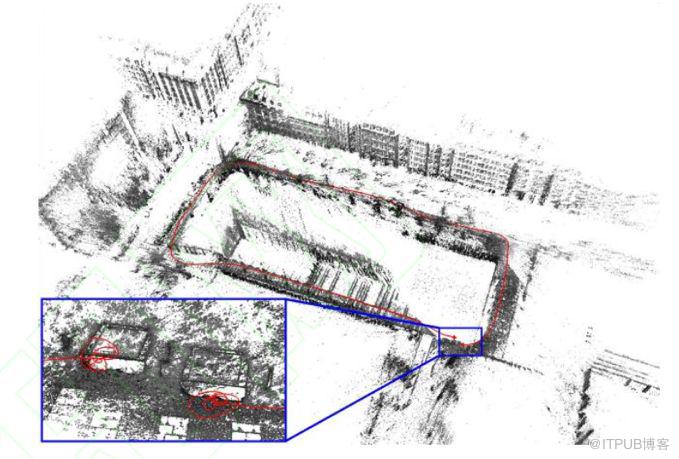
(2) 实际工业应用中,经常采用双目、RGB_D、TOF等深度相机和IMU融合的vSLAM方案
vSLAM实际应用主要方向有两点:一种是通过各种技术的深度相机,简化深度图像的获取难度,从而降低建图难度,另一种是通过视觉和IMU数据的融合,提高视觉里程计(VIO)的精度。
RGB-D传感器上的SLAM方案
RTAB-MAP (Real Time Appearance-Based Mapping)是RGB-D SLAM中比较经典的方案。它实现了RGB-D SLAM中所以应该有的东西:基于特征的视觉里程计、基于词袋的回环检测、后端的位姿图优化,以及点云和三角网格地图。RTAB-MAP支持一些常见的RGB-D和双目传感器,像kinect、Xtion等,且提供实时的定位和建图功能。不过由于集成度较高,更适合作为SLAM应用而非研究。
优点:相比于单目和双目,RGB-D SLAM的原理要简单很多,而且能在CPU上实时建立稠密的地图。
视觉和IMU融合的高精度VIO方案
提出了一种紧耦合、基于非线性优化的IMU与多目视觉的实时融合方法,属于VIO(Visual Inertial Odometry),通过视觉融合IMU做里程计。
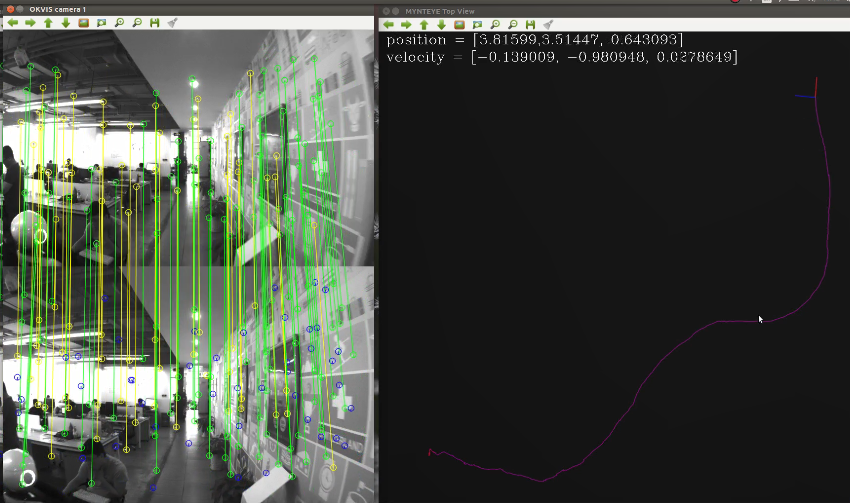
提出了一种基于EKF的IMU与单目视觉的融合方法;基于图像块的滤波实现的VIO。

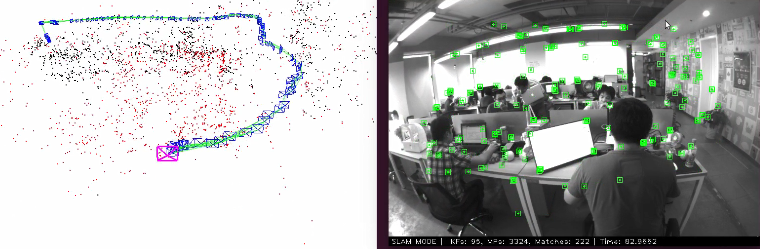
(3) 未来方向:基于深度学习的SLAM
特征匹配方向:

VIO方向:
建图方向:
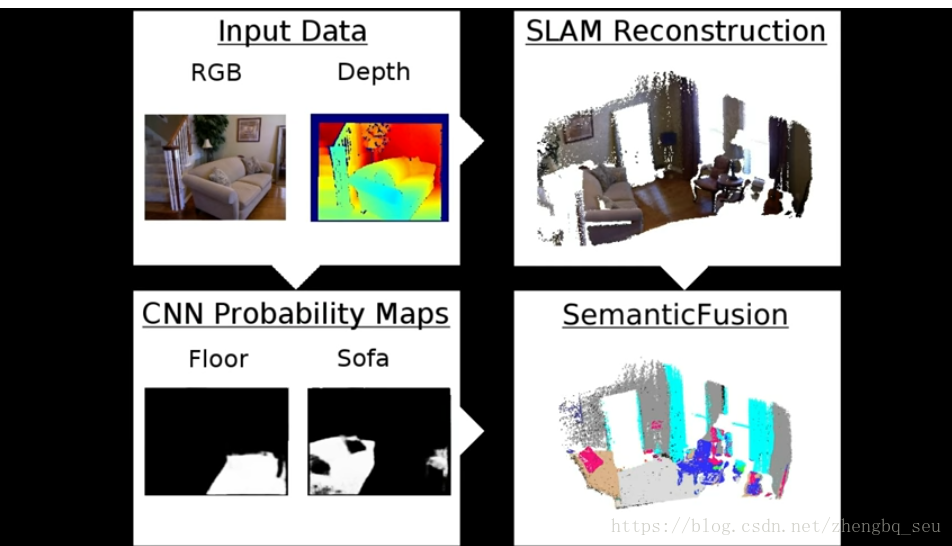
特殊之处:相对于FCN而言,将获取的语义信息投影到Kinect地图里 获取3D的地图 ,一般的语义分割都是图像形态 没有定位信息,这个有相对的三维位置关系

用了ElasticFusion和caffe合成,实现了三维场景的语义分割。






 写留言
写留言
 收藏
收藏
 微博分享
微博分享
 微信
微信
 朋友圈
朋友圈
 QQ
QQ
 微博
微博
 QQ空间
QQ空间
 复制链接
复制链接





















